The Daniell-Kolmogorov extension theorem is one of the first deep theorems of the theory of stochastic processes. It provides existence results for nice probability measures on path (function) spaces. It is however non-constructive and relies on the axiom of choice. In what follows, in order to avoid heavy notations we restrict to the one dimensional case 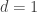 . The multidimensional extension is straightforward and let to the reader.
. The multidimensional extension is straightforward and let to the reader.
Definition. Let  be a stochastic process. For
be a stochastic process. For  we denote by
we denote by  the probability distribution of the random variable
the probability distribution of the random variable  It is therefore a probability measure on
It is therefore a probability measure on  . This probability measure is called a finite dimensional distribution of the process
. This probability measure is called a finite dimensional distribution of the process  .
.
If two processes have the same finite dimensional distributions, then it is clear that the two processes induce the same distribution on the path space  because cylinders generate the
because cylinders generate the  -algebra
-algebra  (see Lecture 2).
(see Lecture 2).
The finite dimensional distributions of a given process satisfy the two following properties: If  and if
and if  is a permutation of the set
is a permutation of the set  , then:
, then:
Conversely,
Theorem (Daniell-Kolmogorov theorem). Assume that we are given for every a probability measure on . Let us assume that these probability measures satisfy:
Then, there is a unique probability measure  on
on  such that for ,
such that for ,  :
:

The Daniell-Kolmogorov theorem is often used to construct processes thanks to the following corollary:
Corollary. Assume given for every a probability measure on . Let us further assume that these measures satisfy the assumptions of the Daniell-Kolmogorov theorem. Then, there exists a probability space  as well as a process defined on this space such that the finite dimensional distributions of are given by the ‘s.
as well as a process defined on this space such that the finite dimensional distributions of are given by the ‘s.
Proof of the corollary:
As a probability space we chose

where is the probability measure given by the Daniell-Kolmogorov theorem. The canonical coordinate process  defined on
defined on  by
by  satisfies the required property.
satisfies the required property. 
We now turn to the proof of the Daniell-Kolmogorov theorem. This proof proceeds in several steps.
As a first step, let us recall the Caratheodory extension theorem that is often useful for the effective construction of measures (for instance the construction of the Lebesgue measure on  ):
):
Theorem (Caratheodory theorem). Let  be a non-empty set and let
be a non-empty set and let  be a family of subsets that satisfy:
be a family of subsets that satisfy:
Let  be the -algebra generated by . If
be the -algebra generated by . If  is -additive measure on
is -additive measure on  which is -finite, then there exists a unique -additive measure on
which is -finite, then there exists a unique -additive measure on  such that for
such that for 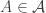 ,
, 
As a first step, we prove the following fact:
Lemma. Let  ,
,  be a sequence of Borel sets that satisfy
be a sequence of Borel sets that satisfy  Let us assume that for every a probability measure
Let us assume that for every a probability measure 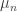 is given on
is given on  and that these probability measures are compatible in the sense that
and that these probability measures are compatible in the sense that

and satisfy:

where  . There exists a sequence of compact sets
. There exists a sequence of compact sets  , , such that:
, , such that:
Proof of the lemma:
For every  , we can find a compact set
, we can find a compact set  such that
such that

and

Let now

It is easily checked that:
Moreover,







With this in hands, we can now turn to the proof of the Daniell-Kolmogorov theorem.
Proof of the Daniell-Kolmogorov theorem:
For the cylinder

where  and where
and where  is a Borel subset of , we define
is a Borel subset of , we define

Thanks to the assumptions on the ‘s, it is seen that such a is well defined and satisfies:

The set of all the possible cylinders  satisfies the assumption of Caratheodory’s theorem. Therefore, in order to conclude, we have to show that is -additive, that is, if
satisfies the assumption of Caratheodory’s theorem. Therefore, in order to conclude, we have to show that is -additive, that is, if  is a sequence of pairwise disjoint cylinders and if
is a sequence of pairwise disjoint cylinders and if  is a cylinder then
is a cylinder then

This is the difficult part of the theorem. Since for 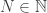 ,
,

we just have to show that

where  .
.
The sequence  is positive decreasing and therefore converges. Let assume that it converges toward
is positive decreasing and therefore converges. Let assume that it converges toward 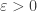 . We shall prove that in that case
. We shall prove that in that case

which is clearly absurd.
Since  is a cylinder, the event
is a cylinder, the event  only involves a coutable sequence of times
only involves a coutable sequence of times  and we may assume (otherwise we can add convenient other sets in the sequence of the 's) that every can be described as follows
and we may assume (otherwise we can add convenient other sets in the sequence of the 's) that every can be described as follows

where , , is a sequence of Borel sets such that

Since we assumed  , we can use the previous lemma to construct a sequence of compact sets , , such that:
, we can use the previous lemma to construct a sequence of compact sets , , such that:
Since 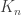 is non-empty, we pick
is non-empty, we pick 
The sequence  has a convergent subsequence
has a convergent subsequence  that converges toward
that converges toward  . The sequence
. The sequence  has a convergent subsequence that converges toward
has a convergent subsequence that converges toward  . By pursuing this process, we obtain a sequence
. By pursuing this process, we obtain a sequence  such that for every ,
such that for every , 
The event

is in , this leads to the expected contradiction. Therefore, the sequence converges toward  , which implies the -additivity of
, which implies the -additivity of
As it has been stressed, the Daniell-Kolmogorov theorem is the basic tool to prove the existence of a stochastic process with given finite dimensional distributions. As an example, let us illustrate how it may be used to prove the existence of the so-called Gaussian processes.
Definition. A real-valued stochastic process defined on  is said to be a Gaussian process if all the finite dimensional distributions of
is said to be a Gaussian process if all the finite dimensional distributions of  are Gaussian random variables.
are Gaussian random variables.
If is a Gaussian process, its finite dimensional distributions can be characterized, through Fourier transform, by its mean function

and its covariance function

We can observe that the covariance function  is symmetric
is symmetric  and positive, that is for
and positive, that is for  and
and  ,
,



Conversely, as an application of the Daniell-Kolmogorov theorem, we let the reader prove as an exercise the following proposition.
Proposition. Let  and let
and let  be a symmetric and positive function. There exists a probability space and a Gaussian process defined on it, whose mean function is
be a symmetric and positive function. There exists a probability space and a Gaussian process defined on it, whose mean function is  and whose covariance function is
and whose covariance function is  .
.

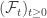


of the filtration
, we have
.









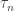















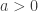












 . Let
. Let  and valued in
and valued in  . We say that
. We say that 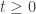 ,
,  .
. , one is able to decide if this property is satisfied or not.
, one is able to decide if this property is satisfied or not.
 is a closed subset of
is a closed subset of  .
.
 is a
is a  , we have that
, we have that  . Let us now consider
. Let us now consider  . We have
. We have
 . Finally, if
. Finally, if  is a sequence of subsets of
is a sequence of subsets of 
 is progressively measurable with respect to the filtration
is progressively measurable with respect to the filtration  .
. ;
; ,
, 
 is a submartingale, is called a supermartingale. Finally, a stochastic process
is a submartingale, is called a supermartingale. Finally, a stochastic process  is a martingale with respect to the filtration
is a martingale with respect to the filtration  is non-decreasing.
is non-decreasing. be a convex function such that for
be a convex function such that for  . Show that the process
. Show that the process  is a submartingale.
is a submartingale. is said to be
is said to be  if there exists a constant
if there exists a constant 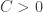 such that for
such that for  ,
,
 is called a modification of the process
is called a modification of the process  if for every
if for every 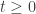 ,
, 
 . If a
. If a  -dimensional process
-dimensional process ![(X_t)_{t\in [0,1]}](https://s0.wp.com/latex.php?latex=%28X_t%29_%7Bt%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) defined on a probability space
defined on a probability space 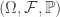 satisfies for
satisfies for ![s,t \in [0,1]](https://s0.wp.com/latex.php?latex=s%2Ct+%5Cin+%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,
![(X_t)_{t \in [0,1]}](https://s0.wp.com/latex.php?latex=%28X_t%29_%7Bt+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) that is a continuous process and whose paths are
that is a continuous process and whose paths are  -Hölder for every
-Hölder for every  .
. . For
. For 






 , we deduce
, we deduce
 such that
such that  and such that for
and such that for  , there exists
, there exists  such that for
such that for  ,
,
 such that for every
such that for every 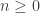 ,
,
 are consequently
are consequently 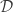 . Indeed, let
. Indeed, let  ,
,  . We can find
. We can find 
 converging toward
converging toward  , such that
, such that  and
and
 that converges toward
that converges toward  and
and 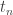 are neighbors in
are neighbors in 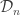 . We have then:
. We have then:




 be the unique continuous function that agrees with
be the unique continuous function that agrees with  on
on  , we set
, we set  . The process
. The process ![(\tilde{X}_t)_{t \in [0,1]}](https://s0.wp.com/latex.php?latex=%28%5Ctilde%7BX%7D_t%29_%7Bt+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=333333&s=0&c=20201002) is the desired modification of
is the desired modification of 

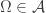 ;
;
 ,
,  ;
; .
.
 .
.  .
. 
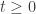 , one is able to decide if an event
, one is able to decide if an event
 denotes the smallest
denotes the smallest  measurable). This notion of information carried by a stochastic process is modeled by filtrations.
measurable). This notion of information carried by a stochastic process is modeled by filtrations. 
 .
.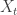 is measurable with respect to
is measurable with respect to 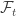 .
. contains all the subsets of
contains all the subsets of  that satisfies
that satisfies
![\forall A \in \mathcal{B}(\mathbb{R}), \{(s,\omega) \in [0,t] \times \Omega, X_s (\omega) \in A \} \in \mathcal{B}([0,t])\otimes \mathcal{F}_t.](https://s0.wp.com/latex.php?latex=%5Cforall+A+%5Cin+%5Cmathcal%7BB%7D%28%5Cmathbb%7BR%7D%29%2C+%5C%7B%28s%2C%5Comega%29+%5Cin+%5B0%2Ct%5D+%5Ctimes+%5COmega%2C+X_s+%28%5Comega%29+%5Cin+A+%5C%7D+%5Cin+%5Cmathcal%7BB%7D%28%5B0%2Ct%5D%29%5Cotimes+%5Cmathcal%7BF%7D_t.++&bg=ffffff&fg=333333&s=0&c=20201002)
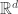 -valued
-valued 
 are called the paths of the process. The application
are called the paths of the process. The application 
 denotes the set of functions
denotes the set of functions  endowed with the
endowed with the 
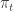 the application that transforms
the application that transforms  into
into 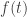 . The stochastic process
. The stochastic process  which is defined on the probability space
which is defined on the probability space  is called the canonical process associated to
is called the canonical process associated to 
 that is, if
that is, if
 denotes here the Borel
denotes here the Borel 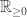 .
. .
. , that is if the paths of
, that is if the paths of 
 . Moreover, a continuous process is measurable:
. Moreover, a continuous process is measurable: is a Borel set in $\mathbb{R}$, then
is a Borel set in $\mathbb{R}$, then![\{ (t,\omega) \in [0,1]\times \Omega, X_t (\omega) \in A \} \in \mathcal{B}(\mathbb{R}_{\ge 0}) \otimes \mathcal{F}.](https://s0.wp.com/latex.php?latex=%5C%7B+%28t%2C%5Comega%29+%5Cin+%5B0%2C1%5D%5Ctimes+%5COmega%2C+X_t+%28%5Comega%29+%5Cin+A+%5C%7D+%5Cin+%5Cmathcal%7BB%7D%28%5Cmathbb%7BR%7D_%7B%5Cge+0%7D%29+%5Cotimes+%5Cmathcal%7BF%7D.++&bg=ffffff&fg=333333&s=0&c=20201002)
![X_t^n=X_{\frac{[2^n t]}{2^n}}, t \in [0,1],](https://s0.wp.com/latex.php?latex=X_t%5En%3DX_%7B%5Cfrac%7B%5B2%5En+t%5D%7D%7B2%5En%7D%7D%2C+t+%5Cin+%5B0%2C1%5D%2C++&bg=ffffff&fg=333333&s=0&c=20201002)
![[ x]](https://s0.wp.com/latex.php?latex=%5B+x%5D&bg=ffffff&fg=333333&s=0&c=20201002) denotes the integer part of
denotes the integer part of  . Since the paths of
. Since the paths of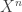 are piecewise constant, we have
are piecewise constant, we have![\{ (t,\omega) \in [0,1]\times \Omega, X^n_t (\omega) \in A \} \in \mathcal{B}(\mathbb{R}_{\ge 0} ) \otimes \mathcal{F}.](https://s0.wp.com/latex.php?latex=%5C%7B+%28t%2C%5Comega%29+%5Cin+%5B0%2C1%5D%5Ctimes+%5COmega%2C+X%5En_t+%28%5Comega%29+%5Cin+A+%5C%7D+%5Cin+%5Cmathcal%7BB%7D%28%5Cmathbb%7BR%7D_%7B%5Cge+0%7D+%29+%5Cotimes+%5Cmathcal%7BF%7D.++&bg=ffffff&fg=333333&s=0&c=20201002)
![\forall t \in [0,1], \omega \in \Omega](https://s0.wp.com/latex.php?latex=%5Cforall+t+%5Cin+%5B0%2C1%5D%2C+%5Comega+%5Cin+%5COmega&bg=ffffff&fg=333333&s=0&c=20201002) , we have
, we have
 ,
,![\{ (t,\omega) \in [k,k+1]\times \Omega, X_t (\omega) \in A \} \in \mathcal{B}(\mathbb{R}_{\ge 0} ) \otimes \mathcal{F}.](https://s0.wp.com/latex.php?latex=%5C%7B+%28t%2C%5Comega%29+%5Cin+%5Bk%2Ck%2B1%5D%5Ctimes+%5COmega%2C+X_t+%28%5Comega%29+%5Cin+A+%5C%7D+%5Cin+%5Cmathcal%7BB%7D%28%5Cmathbb%7BR%7D_%7B%5Cge+0%7D+%29+%5Cotimes+%5Cmathcal%7BF%7D.++&bg=ffffff&fg=333333&s=0&c=20201002)
![\{ (t,\omega) \in \mathbb{R}_{\ge 0} \times \Omega, X_t (\omega) \in A \}=\cup_{k \in \mathbb{N}} \{ (t,\omega) \in [k,k+1] \times \Omega, X_t (\omega) \in A \},](https://s0.wp.com/latex.php?latex=%5C%7B+%28t%2C%5Comega%29+%5Cin+%5Cmathbb%7BR%7D_%7B%5Cge+0%7D+%5Ctimes+%5COmega%2C+X_t+%28%5Comega%29+%5Cin+A+%5C%7D%3D%5Ccup_%7Bk+%5Cin+%5Cmathbb%7BN%7D%7D+%5C%7B+%28t%2C%5Comega%29+%5Cin+%5Bk%2Ck%2B1%5D+%5Ctimes+%5COmega%2C+X_t+%28%5Comega%29+%5Cin+A+%5C%7D%2C++&bg=ffffff&fg=333333&s=0&c=20201002)
 ,
,  , be the set of functions
, be the set of functions  . We denote by
. We denote by  the
the 
 are products of intervals:
are products of intervals: ![I_i=\Pi_{k=1}^d (a^k_i,b^k_i]](https://s0.wp.com/latex.php?latex=I_i%3D%5CPi_%7Bk%3D1%7D%5Ed+%28a%5Ek_i%2Cb%5Ek_i%5D&bg=ffffff&fg=333333&s=0&c=20201002) .
. where
where  and where
and where  are Borel sets in
are Borel sets in  where
where  .
.![\mathcal{T} ([0,1],\mathbb{R})](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BT%7D++%28%5B0%2C1%5D%2C%5Cmathbb%7BR%7D%29&bg=ffffff&fg=333333&s=0&c=20201002) :
:![\{ f \in \mathcal{A}([0,1], \mathbb{R}), \sup_{t\in [0,1]} f(t) <1 \}](https://s0.wp.com/latex.php?latex=%5C%7B+f+%5Cin+%5Cmathcal%7BA%7D%28%5B0%2C1%5D%2C+%5Cmathbb%7BR%7D%29%2C+%5Csup_%7Bt%5Cin+%5B0%2C1%5D%7D+f%28t%29+%3C1++%5C%7D++&bg=ffffff&fg=333333&s=0&c=20201002)
![\{ f \in \mathcal{A}([0,1], \mathbb{R}), \exists t\in [0,1] f(t) =0 \}](https://s0.wp.com/latex.php?latex=%5C%7B+f+%5Cin+%5Cmathcal%7BA%7D%28%5B0%2C1%5D%2C+%5Cmathbb%7BR%7D%29%2C+%5Cexists+t%5Cin+%5B0%2C1%5D+f%28t%29++%3D0+%5C%7D++&bg=ffffff&fg=333333&s=0&c=20201002)
 endowed with the
endowed with the  that is generated by
that is generated by

![\Pi_{k=1}^d (a^k_i,b^k_i]](https://s0.wp.com/latex.php?latex=%5CPi_%7Bk%3D1%7D%5Ed+%28a%5Ek_i%2Cb%5Ek_i%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This
. This  is generated by the open sets of the topology of uniform convergence on compact sets.
is generated by the open sets of the topology of uniform convergence on compact sets. the topology of uniform convergence on compact sets is given by the distance
the topology of uniform convergence on compact sets is given by the distance
 with the structure of a complete, separable, metric space (that is of a
with the structure of a complete, separable, metric space (that is of a 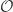 the
the 
 . Thus, we have
. Thus, we have
 ,
, 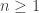 and
and  ,
,



![\mathcal{B} ([0,1],\mathbb{R})](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BB%7D+%28%5B0%2C1%5D%2C%5Cmathbb%7BR%7D%29&bg=ffffff&fg=333333&s=0&c=20201002) :
:![\{ f \in \mathcal{C}([0,1], \mathbb{R}), \sup_{t\in [0,1]} f(t) <1 \}](https://s0.wp.com/latex.php?latex=%5C%7B+f+%5Cin+%5Cmathcal%7BC%7D%28%5B0%2C1%5D%2C+%5Cmathbb%7BR%7D%29%2C+%5Csup_%7Bt%5Cin+%5B0%2C1%5D%7D+f%28t%29+%3C1+%5C%7D++&bg=ffffff&fg=333333&s=0&c=20201002)
![\{ f \in \mathcal{C}([0,1], \mathbb{R}), \exists t\in [0,1] f(t) =0 \}](https://s0.wp.com/latex.php?latex=%5C%7B+f+%5Cin+%5Cmathcal%7BC%7D%28%5B0%2C1%5D%2C+%5Cmathbb%7BR%7D%29%2C+%5Cexists+t%5Cin+%5B0%2C1%5D+f%28t%29+%3D0+%5C%7D++&bg=ffffff&fg=333333&s=0&c=20201002)
 (otherwise, we work with
(otherwise, we work with  ). The first observation is that the price
). The first observation is that the price  , where
, where  are fixed.
are fixed. is of order
is of order  where
where 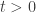 ,
,  . The two above observations imply that for
. The two above observations imply that for 
 , it means that at time
, it means that at time  or to
or to  . According to the second observation, each of this case produces with probability
. According to the second observation, each of this case produces with probability  .
.



 is the Dirac distribution at
is the Dirac distribution at 
 . Let now
. Let now  be fixed times and
be fixed times and 






