It is now time to give some applications of the theory of stochastic differential equations to parabolic second order partial differential equations. In particular we are going to prove that solutions of such equations can represented by using solutions of stochastic differential equations. This representation formula is called the Feynman–Kac formula.
As usual, we consider a filtered probability space  which satisfies the usual conditions and on which is defined a
which satisfies the usual conditions and on which is defined a  -dimensional Brownian motion
-dimensional Brownian motion 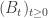 . Again, we consider two functions
. Again, we consider two functions  and
and  and we assume that there exists
and we assume that there exists  such that
such that

Let  be the second order differential operator
be the second order differential operator

where  .
.
As we know, there exists a bicontinuous process  such that for
such that for 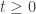 ,
,

Moreover, as it has been stressed before, for every 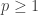 , and
, and 

As a consequence, if  is a Borel function with polynomial growth, we can consider the function
is a Borel function with polynomial growth, we can consider the function

Theorem. For every 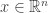 , is a Markov process with semigroup
, is a Markov process with semigroup  . More precisely, for every Borel function with polynomial growth and every
. More precisely, for every Borel function with polynomial growth and every  ,
,

Proof. The key point, here, is to observe that solutions are actually adapted to the natural filtration of the Brownian motion . More precisely, there exists on the space of continuous functions  a predictable functional such that for :
a predictable functional such that for :

Indeed, let us first work on ![[0,T]](https://s0.wp.com/latex.php?latex=%5B0%2CT%5D&bg=ffffff&fg=333333&s=0&c=20201002) where
where  is small enough. In that case, as seen previously, the process
is small enough. In that case, as seen previously, the process  is the unique fixed point of the application
is the unique fixed point of the application 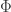 defined by
defined by

Alternatively, one can interpret this by observing that is the limit of the sequence of processes  inductively defined by
inductively defined by

It is easily checked that for each 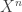 there is a predictable functional
there is a predictable functional 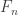 such that
such that

which proves the above claim when is small enough. To get the existence of  for any , we can proceed
for any , we can proceed
With this hands, we can now prove the Markov property. Let  . For , we have
. For , we have


Consequently, from uniqueness of solutions,

We deduce that for a Borel function  with polynomial growth,
with polynomial growth,

because  is a Brownian motion independent of
is a Brownian motion independent of 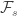

Theorem Let be a Borel function with polynomial growth and assume that the function

is  , that is once differentiable with respect to
, that is once differentiable with respect to  and twice differentiable with respect to
and twice differentiable with respect to  . Then
. Then  solves the Cauchy problem
solves the Cauchy problem

in  , with the initial condition
, with the initial condition  .
.
Proof. Let  and consider the function
and consider the function  . According the previous theorem, we have
. According the previous theorem, we have

As a consequence, the process  is a martingale. But from Ito’s formula the bounded variation part of is
is a martingale. But from Ito’s formula the bounded variation part of is  which is therefore 0. We conclude
which is therefore 0. We conclude

Exercise Show that if  is a
is a  function such that
function such that 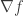 and
and  have polynomial growth, then the function
have polynomial growth, then the function  is . Here, we denote by the Hessian matrix of .
is . Here, we denote by the Hessian matrix of .
Theorem. Let be a Borel function with polynomial growth. Let  be a solution of the Cauchy problem
be a solution of the Cauchy problem
with the initial condition .
If there exists a locally integrable function  and
and  , such that for every and ,
, such that for every and ,

then  .
.
Proof. Let and, as before, consider the function . As a consequence of Ito’s formula, we have

where  is a local martingale with quadratic variation
is a local martingale with quadratic variation  . The conditions on
. The conditions on  and $u$ imply that this quadratic variation is integrable. As a consequence, is a martingale and thus
and $u$ imply that this quadratic variation is integrable. As a consequence, is a martingale and thus 
The previous results may be extended to study parabolic equations with potential as well. More precisely, let  be a bounded function. If is a Borel function with polynomial growth, we define
be a bounded function. If is a Borel function with polynomial growth, we define
 .
.
The same proofs as before will give the following theorems.
Theorem. For every and every Borel function with polynomial growth and every ,

Theorem. Let be a Borel function with polynomial growth and assume that the function

is , that is once differentiable with respect to and twice differentiable with respect to . Then solves the Cauchy problem

in , with the initial condition
.
Theorem. Let be a Borel function with polynomial growth. Let be a solution of the Cauchy problem
with the initial condition . If there exists a locally integrable function and , such that for every and ,
 ,
,
then  .
.

 be a progressively measurable process such that for every
be a progressively measurable process such that for every  ,
,  and
and
 and
and
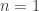 and use the notations introduced in the
and use the notations introduced in the ![f \in L^2([0,1])](https://s0.wp.com/latex.php?latex=f+%5Cin+L%5E2%28%5B0%2C1%5D%29&bg=ffffff&fg=333333&s=0&c=20201002) , we have
, we have
![I_n( f^{\otimes n } )=\int_0^1f(t) \left( \int_{\Delta_{n-1}[0,t]} f^{\otimes {(n-1)}} dB_{t_1} \cdots dB_{t_{n-1}}\right) dB_t,](https://s0.wp.com/latex.php?latex=I_n%28+f%5E%7B%5Cotimes+n+%7D+%29%3D%5Cint_0%5E1f%28t%29+%5Cleft%28+%5Cint_%7B%5CDelta_%7Bn-1%7D%5B0%2Ct%5D%7D+f%5E%7B%5Cotimes+%7B%28n-1%29%7D%7D+dB_%7Bt_1%7D+%5Ccdots+dB_%7Bt_%7Bn-1%7D%7D%5Cright%29+dB_t%2C&bg=ffffff&fg=333333&s=0&c=20201002)

![u_t= f(t)\int_{\Delta_{n-1}[0,t]} f^{\otimes {(n-1)}} dB_{t_1} \cdots dB_{t_{n-1}}](https://s0.wp.com/latex.php?latex=u_t%3D+f%28t%29%5Cint_%7B%5CDelta_%7Bn-1%7D%5B0%2Ct%5D%7D+f%5E%7B%5Cotimes+%7B%28n-1%29%7D%7D+dB_%7Bt_1%7D+%5Ccdots+dB_%7Bt_%7Bn-1%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002) . Since
. Since![f(t) I_{n-1} (f^{\otimes {(n-1)}})= f(t) \left( \int_{\Delta_{n-1}[0,t]} f^{\otimes {(n-1)}} dB_{t_1} \cdots dB_{t_{n-1}}\right)](https://s0.wp.com/latex.php?latex=f%28t%29+I_%7Bn-1%7D+%28f%5E%7B%5Cotimes+%7B%28n-1%29%7D%7D%29%3D+f%28t%29+%5Cleft%28+%5Cint_%7B%5CDelta_%7Bn-1%7D%5B0%2Ct%5D%7D+f%5E%7B%5Cotimes+%7B%28n-1%29%7D%7D+dB_%7Bt_1%7D+%5Ccdots+dB_%7Bt_%7Bn-1%7D%7D%5Cright%29+&bg=ffffff&fg=333333&s=0&c=20201002)
![+ f(t) \int_t^1 f(s)\left( \int_{\Delta_{n-2}[0,s]} f^{\otimes {(n-1)}} dB_{t_1} \cdots dB_{t_{n-2}}\right)dB_s](https://s0.wp.com/latex.php?latex=%2B+f%28t%29+%5Cint_t%5E1+f%28s%29%5Cleft%28+%5Cint_%7B%5CDelta_%7Bn-2%7D%5B0%2Cs%5D%7D+f%5E%7B%5Cotimes+%7B%28n-1%29%7D%7D+dB_%7Bt_1%7D+%5Ccdots+dB_%7Bt_%7Bn-2%7D%7D%5Cright%29dB_s&bg=ffffff&fg=333333&s=0&c=20201002) ,
, can be written as
can be written as  . By continuity of the Malliavin derivative on the space of chaos of order
. By continuity of the Malliavin derivative on the space of chaos of order  and we assume that
and we assume that  and
and  with derivatives at any order (more than 1) bounded.
with derivatives at any order (more than 1) bounded.
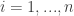 ,
,  ,
,  and for
and for  ,
,
 is the
is the  -th component of
-th component of  . If
. If  , then
, then  .
. for every
for every  and
and
 and that for every
and that for every ![\Psi_n(t)=\sup_{0 \le r \le t} \mathbb{E} \left( \sup_{s \in [r,t]} \| \mathbf{D}_r X_n(s) \|^p \right)< +\infty,](https://s0.wp.com/latex.php?latex=%5CPsi_n%28t%29%3D%5Csup_%7B0+%5Cle+r+%5Cle+t%7D+%5Cmathbb%7BE%7D+%5Cleft%28+%5Csup_%7Bs+%5Cin+%5Br%2Ct%5D%7D+%5C%7C+%5Cmathbf%7BD%7D_r+X_n%28s%29+%5C%7C%5Ep+%5Cright%29%3C+%2B%5Cinfty%2C&bg=ffffff&fg=333333&s=0&c=20201002)

 converges to
converges to  in
in  and that the sequence
and that the sequence  is bounded. As a consequence
is bounded. As a consequence 
 is the first variation process defined by
is the first variation process defined by
 the Malliavin matrix of
the Malliavin matrix of  . From the previous corollary, we deduce that
. From the previous corollary, we deduce that
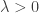 such that for every
such that for every 
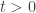 and
and  is invertible with inverse in
is invertible with inverse in  is invertible and that its inverse solves a linear equation, we deduce that for every
is invertible and that its inverse solves a linear equation, we deduce that for every 
 is invertible with inverse in
is invertible with inverse in 



 has moments in
has moments in  on which is defined a Brownian motion
on which is defined a Brownian motion  , and we assume that
, and we assume that  is the usual completion of the natural filtration of
is the usual completion of the natural filtration of  that is particularly suited to the study of the space
that is particularly suited to the study of the space  . For simplicity of the exposition, we restrict ourselves to the case where the Brownian motion
. For simplicity of the exposition, we restrict ourselves to the case where the Brownian motion 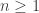 , we denote by
, we denote by 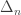 the simplex
the simplex  and if
and if  ,
,


 .
.
 are orthogonal in
are orthogonal in  . It is easily seen that
. It is easily seen that ![\left\{ I_n (f^{\otimes n}), f \in L^2([0,1]) \right\},](https://s0.wp.com/latex.php?latex=%5Cleft%5C%7B+I_n+%28f%5E%7B%5Cotimes+n%7D%29%2C+f+%5Cin+L%5E2%28%5B0%2C1%5D%29+%5Cright%5C%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 the map
the map  such that
such that  . It turns out that
. It turns out that  can be computed by using
can be computed by using 
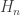 , we see that for every
, we see that for every  ,
,
![I_n (f^{\otimes n})=\| f \|^n_{L^2([0,1])} H_n \left(\frac{ \int_0^1 f(s) dB_s}{\| f \|_{L^2([0,1])} } \right) .](https://s0.wp.com/latex.php?latex=I_n+%28f%5E%7B%5Cotimes+n%7D%29%3D%5C%7C+f+%5C%7C%5En_%7BL%5E2%28%5B0%2C1%5D%29%7D+H_n+%5Cleft%28%5Cfrac%7B+%5Cint_0%5E1+f%28s%29+dB_s%7D%7B%5C%7C+f+%5C%7C_%7BL%5E2%28%5B0%2C1%5D%29%7D+%7D+%5Cright%29+.&bg=ffffff&fg=333333&s=0&c=20201002)
 ,
,![\exp \left( \lambda \int_0^1 f(s) dB_s-\frac{\lambda^2}{2} \int_0^1 f(s)^2 ds \right)=\sum_{n=0}^{+\infty} \lambda^n \| f \|^n_{L^2([0,1])} H_n \left(\frac{ \int_0^1 f(s) dB_s}{\| f \|_{L^2([0,1])} } \right) .](https://s0.wp.com/latex.php?latex=%5Cexp+%5Cleft%28+%5Clambda+%5Cint_0%5E1+f%28s%29+dB_s-%5Cfrac%7B%5Clambda%5E2%7D%7B2%7D+%5Cint_0%5E1+f%28s%29%5E2+ds++%5Cright%29%3D%5Csum_%7Bn%3D0%7D%5E%7B%2B%5Cinfty%7D+%5Clambda%5En+%5C%7C+f+%5C%7C%5En_%7BL%5E2%28%5B0%2C1%5D%29%7D+H_n+%5Cleft%28%5Cfrac%7B+%5Cint_0%5E1+f%28s%29+dB_s%7D%7B%5C%7C+f+%5C%7C_%7BL%5E2%28%5B0%2C1%5D%29%7D+%7D+%5Cright%29+.&bg=ffffff&fg=333333&s=0&c=20201002)


![M_1(\lambda)=1+\sum_{k=1}^n \lambda^k I_k( f^{\otimes k})+\lambda^{n+1} \int_0^1 M_tf(t)\left(\int_{\Delta_n([0,t])} f(t_1)\cdots f(t_n) dB_{t_1}...dB_{t_n}\right) dB_t.](https://s0.wp.com/latex.php?latex=M_1%28%5Clambda%29%3D1%2B%5Csum_%7Bk%3D1%7D%5En+%5Clambda%5Ek+I_k%28+f%5E%7B%5Cotimes+k%7D%29%2B%5Clambda%5E%7Bn%2B1%7D+%5Cint_0%5E1+M_tf%28t%29%5Cleft%28%5Cint_%7B%5CDelta_n%28%5B0%2Ct%5D%29%7D++f%28t_1%29%5Ccdots+f%28t_n%29++dB_%7Bt_1%7D...dB_%7Bt_n%7D%5Cright%29+dB_t.&bg=ffffff&fg=333333&s=0&c=20201002)
![I_n( f^{\otimes n})=\frac{1}{n!} \frac{ d^k M_1}{d \lambda^n}(0)=\| f \|^n_{L^2([0,1])} H_n \left(\frac{ \int_0^1 f(s) dB_s}{\| f \|_{L^2([0,1])} } \right) \square](https://s0.wp.com/latex.php?latex=I_n%28+f%5E%7B%5Cotimes+n%7D%29%3D%5Cfrac%7B1%7D%7Bn%21%7D+%5Cfrac%7B+d%5Ek+M_1%7D%7Bd+%5Clambda%5En%7D%280%29%3D%5C%7C+f+%5C%7C%5En_%7BL%5E2%28%5B0%2C1%5D%29%7D+H_n+%5Cleft%28%5Cfrac%7B+%5Cint_0%5E1+f%28s%29+dB_s%7D%7B%5C%7C+f+%5C%7C_%7BL%5E2%28%5B0%2C1%5D%29%7D+%7D+%5Cright%29+%5Csquare&bg=ffffff&fg=333333&s=0&c=20201002)
 , the spaces
, the spaces  are othogonal. We have the following orthogonal decomposition of
are othogonal. We have the following orthogonal decomposition of 

 is orthogonal to
is orthogonal to  , then
, then  ,
, 
 is easy to describe by using the Wiener chaos expansion. The keypoint is the following proposition:
is easy to describe by using the Wiener chaos expansion. The keypoint is the following proposition: , then
, then  and
and  where for
where for  ,
,
 is a smooth cylindric functional and
is a smooth cylindric functional and![\mathbf{D}_t F =\| f \|^{n-1}_{L^2([0,1])} f(t) H'_n \left(\frac{ \int_0^1 f(s) dB_s}{\| f \|_{L^2([0,1])} } \right).](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BD%7D_t+F+%3D%5C%7C+f+%5C%7C%5E%7Bn-1%7D_%7BL%5E2%28%5B0%2C1%5D%29%7D+f%28t%29+H%27_n+%5Cleft%28%5Cfrac%7B+%5Cint_0%5E1+f%28s%29+dB_s%7D%7B%5C%7C+f+%5C%7C_%7BL%5E2%28%5B0%2C1%5D%29%7D+%7D+%5Cright%29.&bg=ffffff&fg=333333&s=0&c=20201002)
 , therefore we have
, therefore we have![\mathbf{D}_t F =\| f \|^{n-1}_{L^2([0,1])} f(t) H_{n-1} \left(\frac{ \int_0^1 f(s) dB_s}{\| f \|_{L^2([0,1])} } \right) =f(t) I_{n-1} (f^{\otimes {(n-1)}}).](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BD%7D_t+F++%3D%5C%7C+f+%5C%7C%5E%7Bn-1%7D_%7BL%5E2%28%5B0%2C1%5D%29%7D+f%28t%29+H_%7Bn-1%7D+%5Cleft%28%5Cfrac%7B+%5Cint_0%5E1+f%28s%29+dB_s%7D%7B%5C%7C+f+%5C%7C_%7BL%5E2%28%5B0%2C1%5D%29%7D+%7D+%5Cright%29++%3Df%28t%29+I_%7Bn-1%7D+%28f%5E%7B%5Cotimes+%7B%28n-1%29%7D%7D%29.&bg=ffffff&fg=333333&s=0&c=20201002)
 We now observe that
We now observe that ![\left\{ I_n (f^{\otimes n}), f \in L^2([0,1]) \right\}](https://s0.wp.com/latex.php?latex=%5Cleft%5C%7B+I_n+%28f%5E%7B%5Cotimes+n%7D%29%2C+f+%5Cin+L%5E2%28%5B0%2C1%5D%29+%5Cright%5C%7D&bg=ffffff&fg=333333&s=0&c=20201002)



 ,
, 
 be a sequence in
be a sequence in 
 ,
, 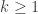 if and only if
if and only if
 . Show that for
. Show that for  .
. , we set
, we set .
. as a square integrable random process indexed by
as a square integrable random process indexed by ![[0,1]^{k}](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5E%7Bk%7D&bg=ffffff&fg=333333&s=0&c=20201002) and valued in
and valued in  . By using the integration by parts formula, it is possible to prove, as we did it in the previous Lecture, that for any
. By using the integration by parts formula, it is possible to prove, as we did it in the previous Lecture, that for any  , the operator
, the operator  is closable on
is closable on 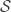 . We denote by
. We denote by  the domain of
the domain of ![\left\| F\right\| _{k,p}=\left( \mathbb{E}\left( F^{p}\right) +\sum_{j=1}^k \mathbb{E}\left( \left\| \mathbf{D}^j F\right\|_{\mathbf{L}^2 ([0,1]^j, \mathbb{R}^n)}^{p}\right) \right)^{\frac{1}{p}}](https://s0.wp.com/latex.php?latex=%5Cleft%5C%7C+F%5Cright%5C%7C+_%7Bk%2Cp%7D%3D%5Cleft%28+%5Cmathbb%7BE%7D%5Cleft%28+F%5E%7Bp%7D%5Cright%29+%2B%5Csum_%7Bj%3D1%7D%5Ek+%5Cmathbb%7BE%7D%5Cleft%28+%5Cleft%5C%7C+%5Cmathbf%7BD%7D%5Ej+F%5Cright%5C%7C_%7B%5Cmathbf%7BL%7D%5E2+%28%5B0%2C1%5D%5Ej%2C+%5Cmathbb%7BR%7D%5En%29%7D%5E%7Bp%7D%5Cright%29+%5Cright%29%5E%7B%5Cfrac%7B1%7D%7Bp%7D%7D&bg=ffffff&fg=333333&s=0&c=20201002) ,
,
 be a
be a  measurable random vector such that:
measurable random vector such that: ,
,  ;
;
 ,
,
 is often called the Malliavin matrix of the random vector
is often called the Malliavin matrix of the random vector  is a smooth function then for
is a smooth function then for  , we denote
, we denote
 be a probability measure on
be a probability measure on  ,
,
 ,
,  . Then
. Then  ,
,  and
and  . Let
. Let 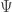 be a smooth function on
be a smooth function on  on the ball
on the ball  and
and  outside the ball
outside the ball  . Let
. Let  be the measure on
be the measure on 
 . Now, if we can prove that under the above assumption
. Now, if we can prove that under the above assumption  has a smooth density because
has a smooth density because  are arbitrary. Let
are arbitrary. Let
 is rapidly decreasing (apply the inequality with
is rapidly decreasing (apply the inequality with  ). We conclude that
). We conclude that 
 , we easily deduce that
, we easily deduce that  and that
and that






 such that,
such that,
 measurable real valued random variable
measurable real valued random variable 
![h^i \in \mathbf{L}^2 ([0,1], \mathbb{R}^n)](https://s0.wp.com/latex.php?latex=h%5Ei+%5Cin+%5Cmathbf%7BL%7D%5E2+%28%5B0%2C1%5D%2C+%5Cmathbb%7BR%7D%5En%29&bg=ffffff&fg=333333&s=0&c=20201002) and
and  is a
is a  function such that
function such that  given by
given by
 as an (unbounded) operator from the space
as an (unbounded) operator from the space  into the Banach space
into the Banach space
 be a progressively measurable such that
be a progressively measurable such that  . We have
. We have

 and denote
and denote


 ,
,
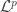 ,
,  be a sequence in
be a sequence in  to
to  and such that
and such that  converges in
converges in  . We want to prove that
. We want to prove that  . Let
. Let 


 is arbitrary, we conclude
is arbitrary, we conclude  is the closure of
is the closure of ![\left\| F\right\| _{1,p}=\left( \mathbb{E}\left( F^{p}\right) + \mathbb{E}\left( \left\| \mathbf{D} F\right\|_{\mathbf{L}^2 ([0,1], \mathbb{R}^n)}^{p}\right) \right)^{\frac{1}{p}},](https://s0.wp.com/latex.php?latex=%5Cleft%5C%7C+F%5Cright%5C%7C+_%7B1%2Cp%7D%3D%5Cleft%28+%5Cmathbb%7BE%7D%5Cleft%28+F%5E%7Bp%7D%5Cright%29+%2B+%5Cmathbb%7BE%7D%5Cleft%28+%5Cleft%5C%7C+%5Cmathbf%7BD%7D+F%5Cright%5C%7C_%7B%5Cmathbf%7BL%7D%5E2+%28%5B0%2C1%5D%2C+%5Cmathbb%7BR%7D%5En%29%7D%5E%7Bp%7D%5Cright%29+%5Cright%29%5E%7B%5Cfrac%7B1%7D%7Bp%7D%7D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
 of
of  with
with  which is characterized by the duality formula
which is characterized by the duality formula
 contains the set of progressively measurable processes
contains the set of progressively measurable processes  such that
such that  and in that case,
and in that case,  The operator
The operator 

 be a filtered probability space which satisfies the usual conditions. It is often useful to use the language of
be a filtered probability space which satisfies the usual conditions. It is often useful to use the language of  ,
,  -adapted real valued local martingale and if
-adapted real valued local martingale and if  is an
is an  , then by definition the Stratonovitch integral of
, then by definition the Stratonovitch integral of  is defined as
is defined as
 is the Itō integral of
is the Itō integral of  is the quadratic covariation at time
is the quadratic covariation at time  be a
be a 
 be a non empty open set. A smooth vector field
be a non empty open set. A smooth vector field  on
on 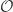 is simply a smooth map
is simply a smooth map
 as follows:
as follows:
 , linear over
, linear over  , satisfying for
, satisfying for  ,
, 
 be a
be a  -dimensional Brownian motion and consider
-dimensional Brownian motion and consider 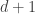
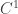 vector fields
vector fields  ,
, 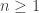 ,
,  . By using the language of vector fields and Stratonovitch integrals, the fundamental theorem for the existence and the uniqueness of solutions for stochastic differential equations is the following:
. By using the language of vector fields and Stratonovitch integrals, the fundamental theorem for the existence and the uniqueness of solutions for stochastic differential equations is the following: are bounded vector fields with bounded derivatives up to order 2. Let
are bounded vector fields with bounded derivatives up to order 2. Let  such that for
such that for 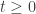 ,
,
 .
.
 ,
,  is the vector field given by
is the vector field given by



 is the solution of a stochastic differential equation
is the solution of a stochastic differential equation
 ,
,
 . It is remarkable that this property still holds when
. It is remarkable that this property still holds when 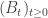 be a standard Brownian motion and let
be a standard Brownian motion and let  is a standard Brownian motion independent from
is a standard Brownian motion independent from  .
.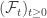 . We first assume
. We first assume  Let
Let  . Applying Doob’s stopping theorem to the martingale
. Applying Doob’s stopping theorem to the martingale  with the stopping times
with the stopping times  and
and  , yields:
, yields:

 are therefore independent and stationary. The conclusion then easily follows. If
are therefore independent and stationary. The conclusion then easily follows. If  and from the previous result the finite dimensional distributions
and from the previous result the finite dimensional distributions  do not depend on
do not depend on  and are the same as a Brownian motion. We can then let
and are the same as a Brownian motion. We can then let  to conclude
to conclude 
 be a bounded closed set in
be a bounded closed set in  , we denote
, we denote  . If
. If  , we define
, we define .
. be a bounded Borel function and assume that the function
be a bounded Borel function and assume that the function  is
is 

